
Austrian Science Minister publicly announces to leave CERN - mountainfolks withdraw from the suisse caves into their own
The Austrian Science Minister Johannes Hahn wants to free 20mio EUR budget per year by leaving the CERN consortium. This would allow him to move the money directly to his buddies at local universities to support "european research".
Well, then please also close down your WWW servers at http://www.bmwf.gv.at/ because we are currently celebrating 20 years of this CERN invention.
In their own words: "Durch die frei werdenden CERN-Mittel bieten wir den Universitäten eine europäische Forschungsperspektive". - "By freeing funds from CERN we offer the Universities a european Research Perspective". Well, I wonder why the Universities are currently cut off from EU funds - because they are not writing enough proposals? And CERN is international, its not Europen. Even better to stay there.
Here is the press release (7.5.2009).
Here is the protest platform:
http://sos.teilchen.at/
"Der wissenschaftliche Output ist unbestritten, aber die Sichtbarkeit kleiner Staaten in Experimenten mit über 2.000 Mitgliedern eher gering." - meaning: with over 2000 scientists, the Austrians don't always appear in front row, and this is not enough great publicity for my ministry. What the fuck? Its about science, not about a minister showing off in front of cameras. Be happy if you can send your students to meet the other 2000 top phycicists in the world, in a highly competitive atmosphere.
So, lets leave the underground caves in switzerland, filled with mysterious magnets, to go back to our own caves at the Austrian Research Centers, a political wonderland of science funding.
Well, then please also close down your WWW servers at http://www.bmwf.gv.at/ because we are currently celebrating 20 years of this CERN invention.
In their own words: "Durch die frei werdenden CERN-Mittel bieten wir den Universitäten eine europäische Forschungsperspektive". - "By freeing funds from CERN we offer the Universities a european Research Perspective". Well, I wonder why the Universities are currently cut off from EU funds - because they are not writing enough proposals? And CERN is international, its not Europen. Even better to stay there.
Here is the press release (7.5.2009).
Here is the protest platform:
http://sos.teilchen.at/
"Der wissenschaftliche Output ist unbestritten, aber die Sichtbarkeit kleiner Staaten in Experimenten mit über 2.000 Mitgliedern eher gering." - meaning: with over 2000 scientists, the Austrians don't always appear in front row, and this is not enough great publicity for my ministry. What the fuck? Its about science, not about a minister showing off in front of cameras. Be happy if you can send your students to meet the other 2000 top phycicists in the world, in a highly competitive atmosphere.
So, lets leave the underground caves in switzerland, filled with mysterious magnets, to go back to our own caves at the Austrian Research Centers, a political wonderland of science funding.
|
leobard - 12. May, 10:34
|
|
- add comment - 0 trackbacks


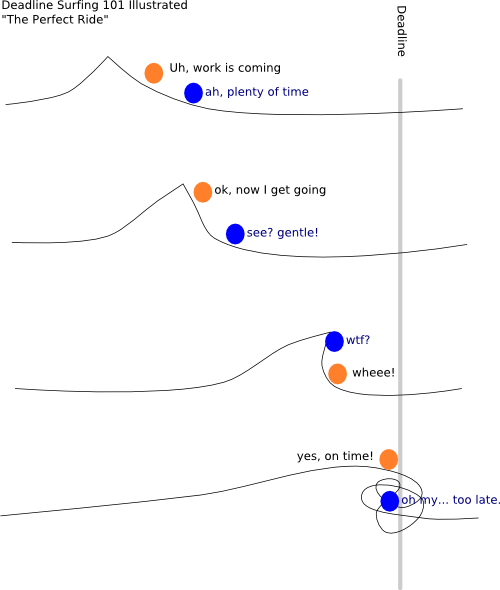
 (c) dude crush, flickr
(c) dude crush, flickr (c) vaguely artistic
(c) vaguely artistic (c) coast guard bm
(c) coast guard bm (c) localsurfer
(c) localsurfer (c) soulsurfer3 on flickr
(c) soulsurfer3 on flickr









{kind=link}
storing files
Caouette from Prix pose carrelage